|
|
|
|
|

|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
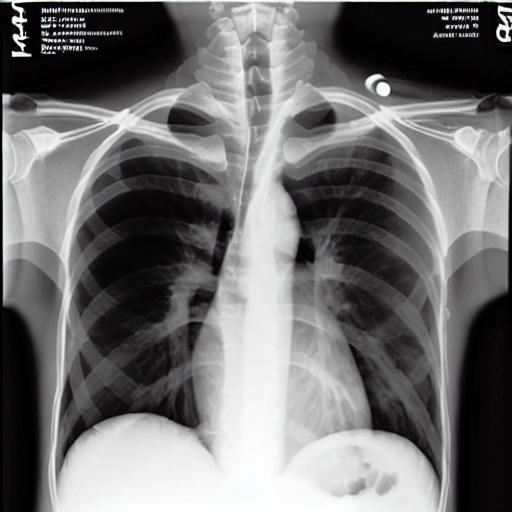
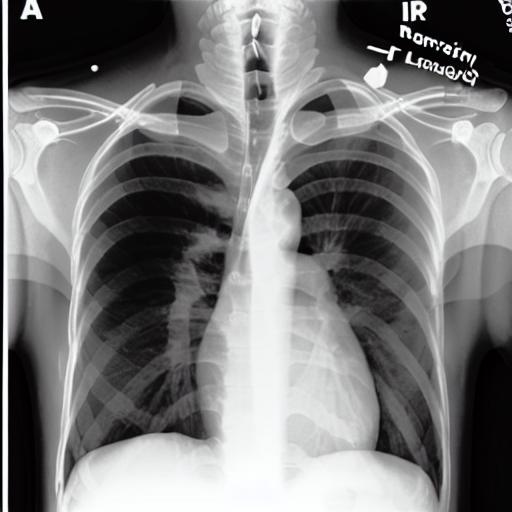
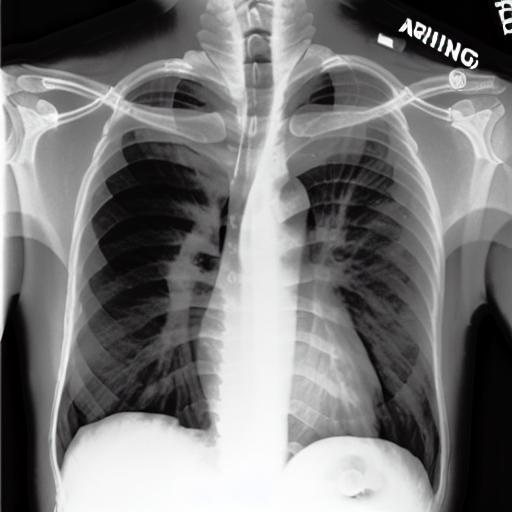
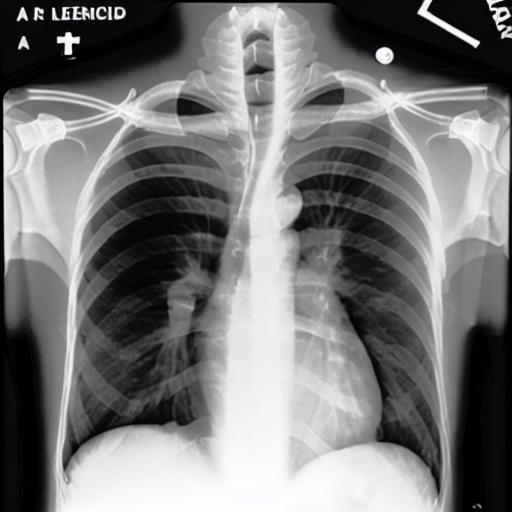
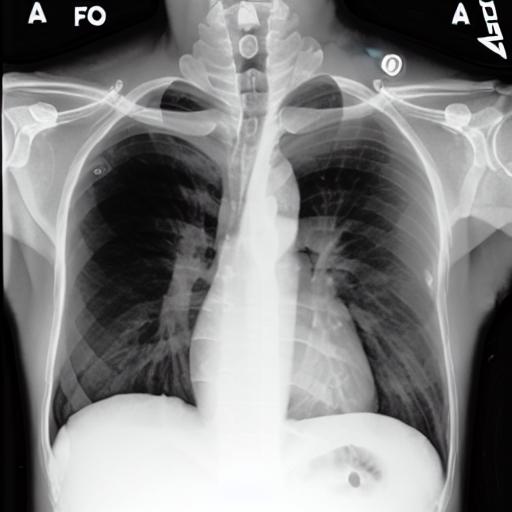
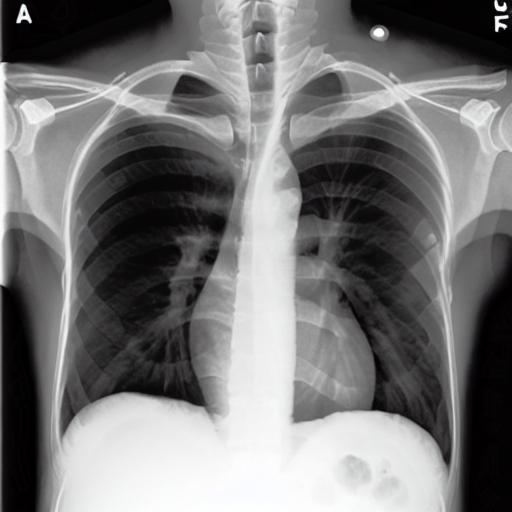
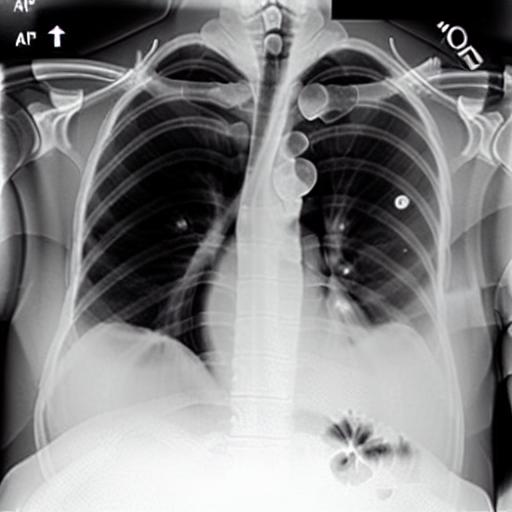
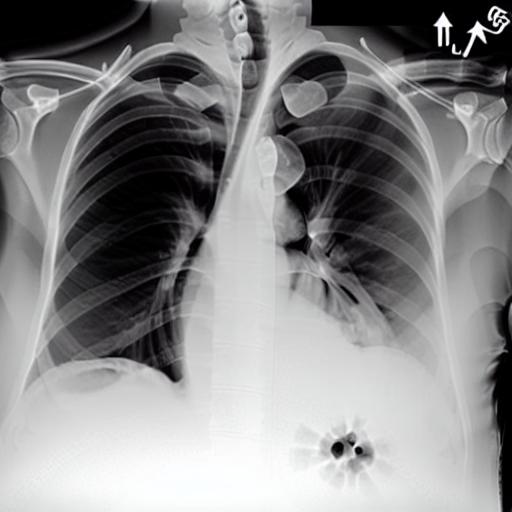
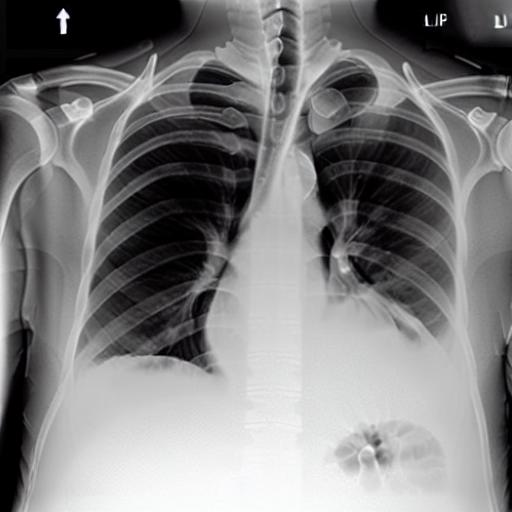
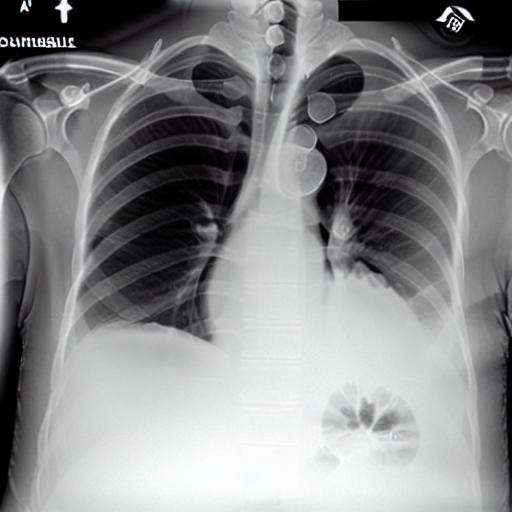
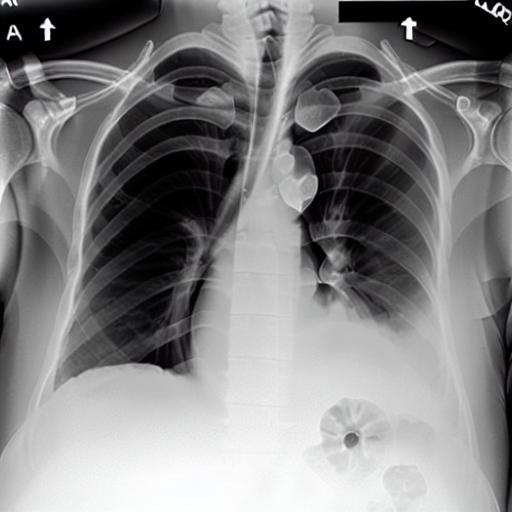
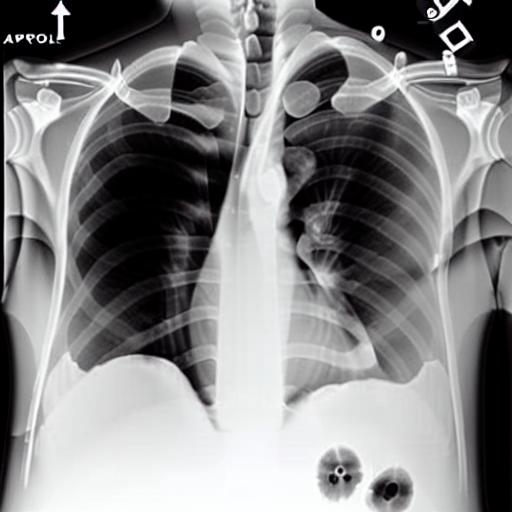
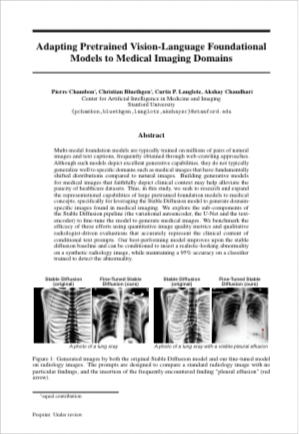
Multi-modal foundation models are typically trained on millions of pairs of natural images and text captions, frequently obtained through web-crawling approaches. Although such models depict excellent generative capabilities, they do not typically generalize well to specific domains such as medical images that have fundamentally shifted distributions compared to natural images. Building generative models for medical images that faithfully depict clinical context may help alleviate the paucity of healthcare datasets. Thus, in this study, we seek to research and expand the capabilities of large pretrained foundation models to medical concepts, specifically for leveraging the Stable Diffusion model to generate domain-specific images found in medical imaging. We explore the main sub-components of the Stable Diffusion pipeline (the variational autoencoder, the U-Net and the text-encoder) to fine-tune the model to generate medical images. We benchmark the efficacy of these efforts using quantitative image quality metrics, and perform qualitative evaluations by a trained radiologist to evaluate that the generated images accurately represent the medical content of conditional text prompts. Our best-performing model improves upon the Stable Diffusion baseline and can be conditioned to insert a realistic-looking abnormality on a synthetic radiology image, while maintaining a 95% accuracy on a classifier trained to detect the abnormality. |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
P. Chambon, C. Bluethgen, CP. Langlotz, A. Chaudhari Adapting Pretrained Vision-Language Foundational Models to Medical Imaging Domains. In Proceedings, 2022. (hosted on ArXiv) |
AcknowledgementsResearch reported in this publication was made possible in part by the National Institute of Biomedical Imaging and Bioengineering (NIBIB) of the National Institutes of Health, which funded PC under contracts 75N92020C00008 and 75N92020C00021. CB received support from the Swiss Society of Radiology and the Kurt and Senta Herrmann-Foundation, unrelated to this work. We acknowledge the support of this work by the Wu Tsai Human Performance Alliance at Stanford University and the Joe and Clara Tsai Foundation. |
|
The information provided on this project site, including the generated images, does not contain or is substitute for any professional medical or health advice. The information is provided in good faith for general informational, research and educational purposes only. The authors make no warranty of any kind, express or implied, regarding the accuracy, validity, reliability, or completeness of any information on the site. Before taking any actions based on the presented information, we encourage you to consult with appropriate medical professionals. THE USE OR RELIANCE OF ANY INFORMATION CONTAINED ON THE SITE IS SOLELY AT YOUR OWN RISK. |